“Three months ago, this attack came from Taiwan. We need to be honest. I will be straight today. From Taiwan,” he said. “And Taiwan, the Foreign Ministry also, they know the campaign. They didn’t disassociate themselves. They even started criticizing me in the middle of all that insult and slur, but I didn’t care.”
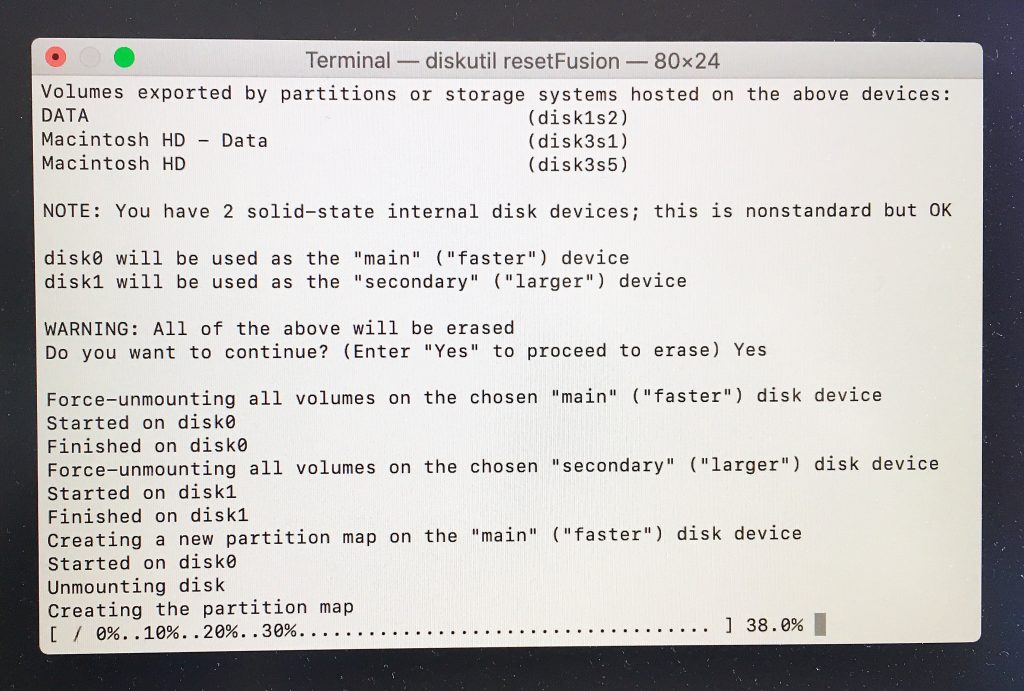
這時候,提示有兩塊硬碟,並且兩塊都是SSD, this is nonstandard but OK. 接下來我們輸入Yes,注意Y要大寫,就會開始對兩塊硬碟進行初始化分區,創建分區表的操作。注意!注意!注意!TimeMachine只會備份操作系統所在的那塊硬碟,如果你的第二塊硬碟上有數據,則需要手動備份,由於我的第二塊硬碟上沒有什麼重要的數據,這裏就沒有進行備份操作,當你確認後,你的兩塊硬碟都會被重新分區。
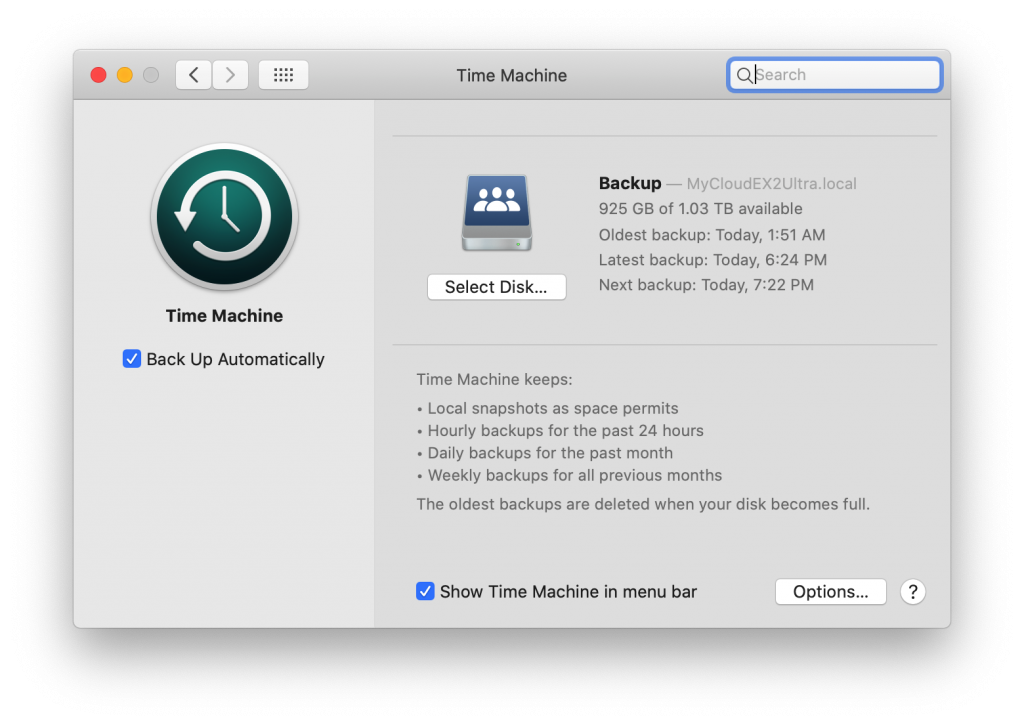
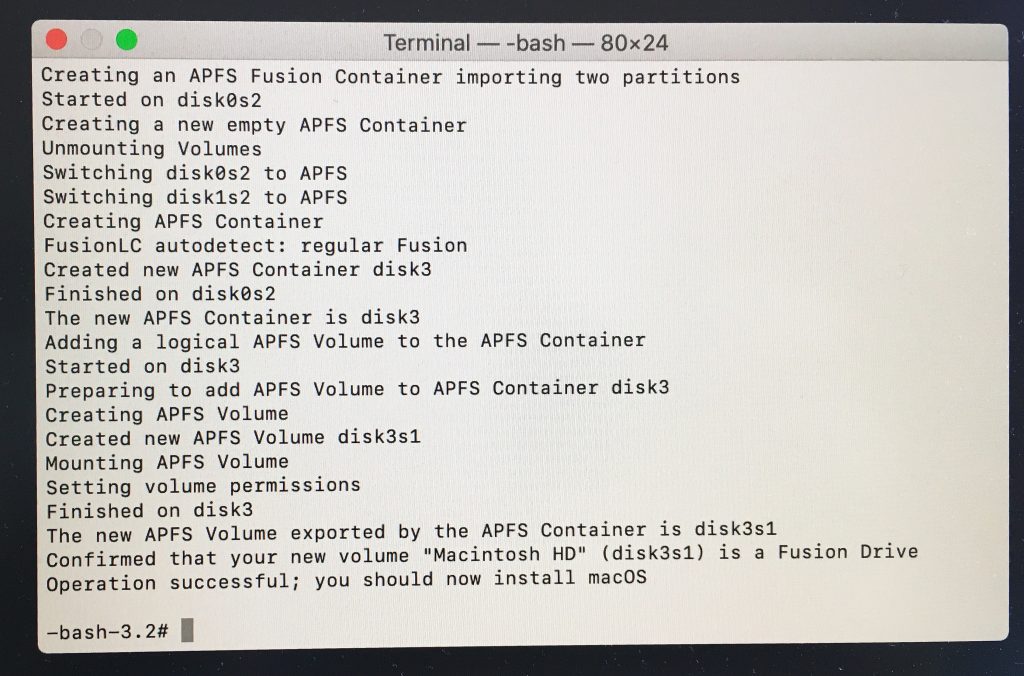
創建FusionDrive的速度很快,大概一兩分鐘就好了,you should now install macOS.
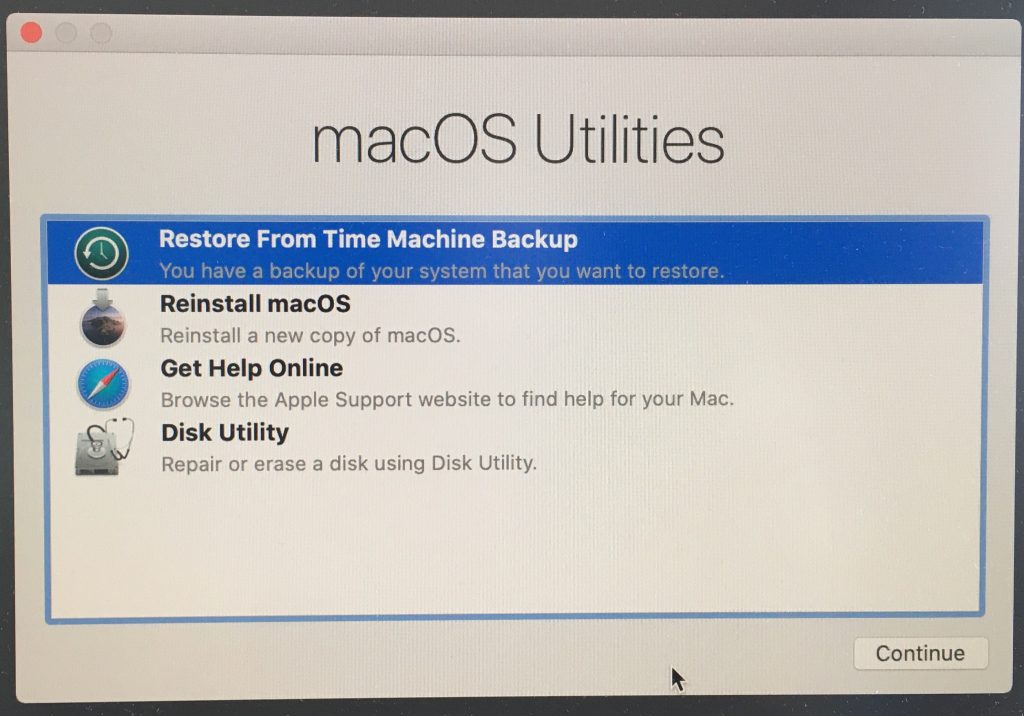
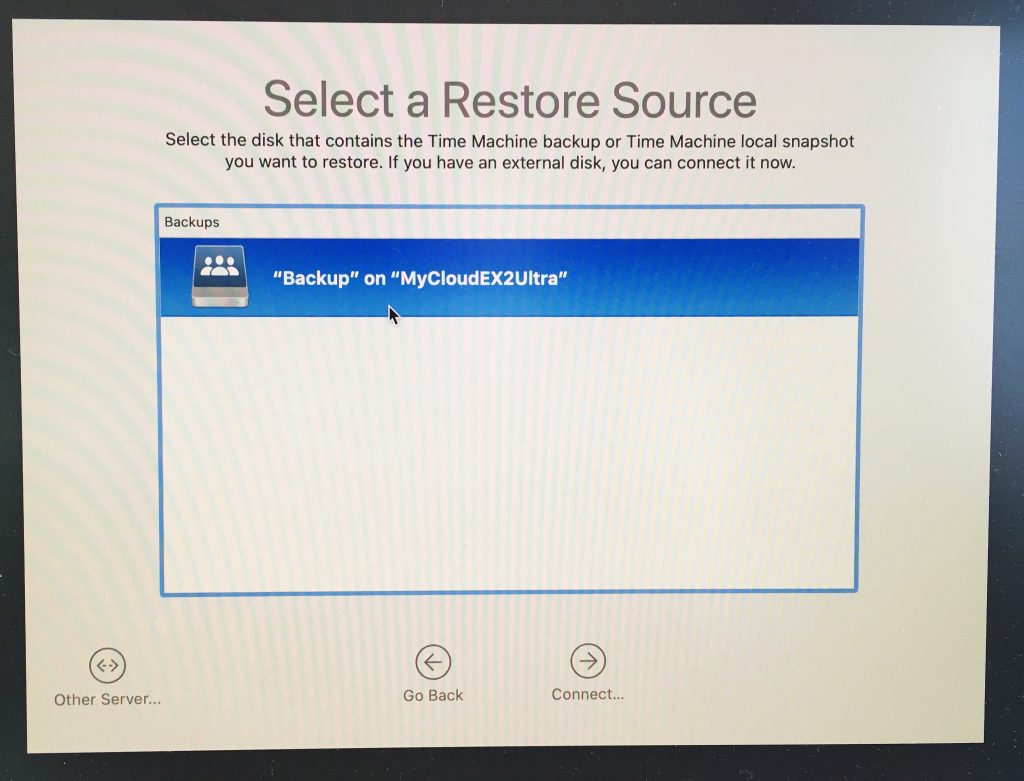
這裏可以選擇全新安裝,全新安裝的話,可以透過網路,下載最新的macOS鏡像,然後解壓縮,安裝,也可以透過外置硬碟或是網路存儲的TimeMachine備份來進行恢復,這裏我選擇Restore from Time Machine Backup。
Google Duo的局限性在於,它每次最多只能邀請12個人進入討論,這和Zoom提供的免費版100個人限制相去甚遠,Skype的人頭限制雖然是250個人,但是Skype需要註冊,沒有便捷的參與渠道,最根本的是上面兩者都沒有會議相關的功能,比如禁止參與者發聲。市面上幾乎沒有和Zoom相同的軟體進行競爭,這是疫情期間他可以爆紅的原因,但隨著疫情趨緩,他逐漸回歸到企業客戶也不是什麼難以預料的事情。